About the post
Lets investigate how the Finagle client helps us to write resilient applications. The Finagle client is a part of an open source initiative from Twitter called Finagle, a RCP system, read more about it here.
This is not some sort of expert instruction of how to configure and use Finagle, it is more of one persons (i.e my) journey towards an understanding of what Finagle has to offer. Most likely the person (yeah, once again myself) will misunderstand things, but that’s what learning is all about, right? Learning from the mistakes.
What is resilience?
To be able to write resilient applications we must first understand what it means to be resilient. Here is the definition from the dictionary:
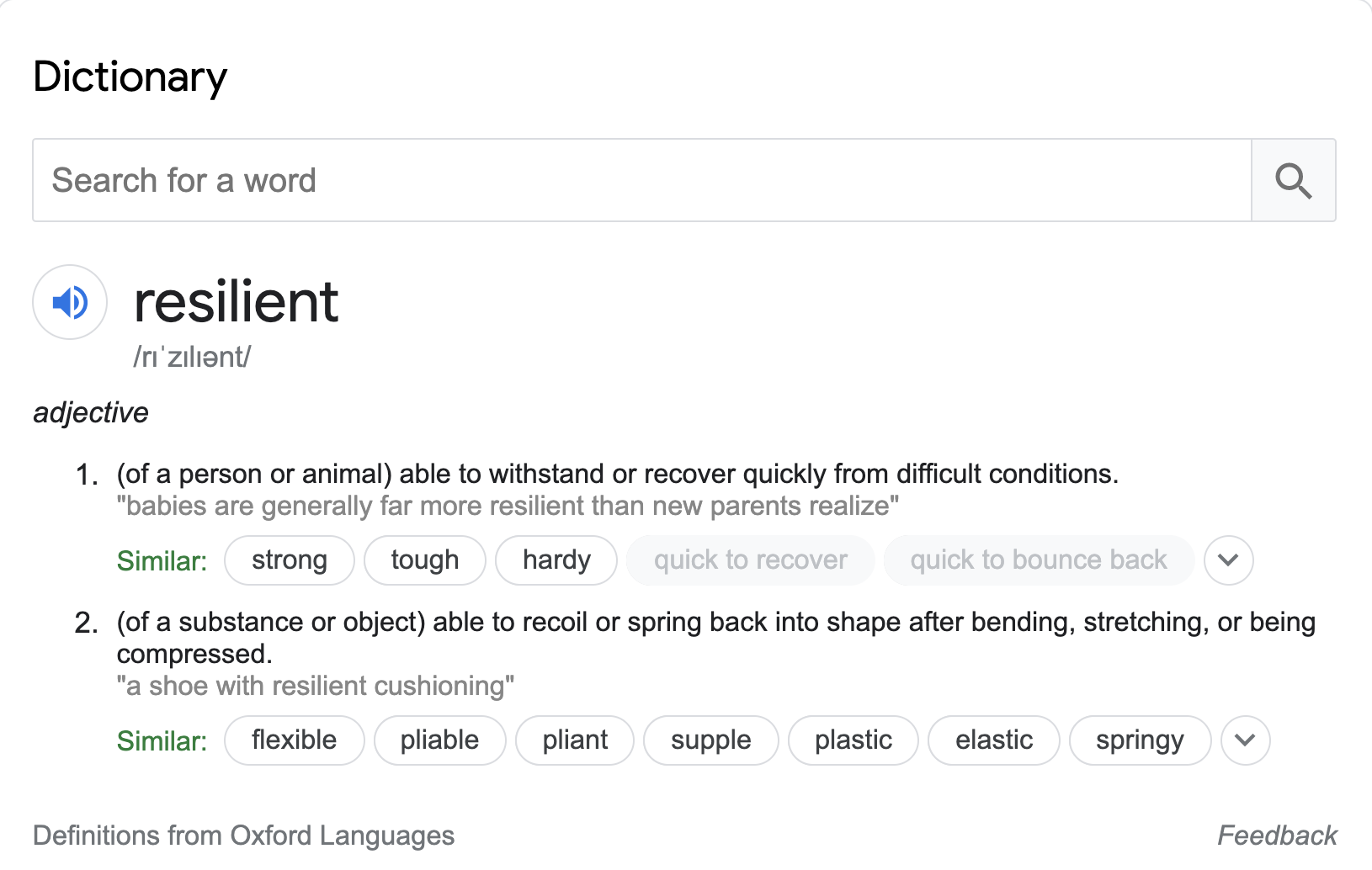
The essence of resilient seems to be an ability to recover from a difficult situation. How does that apply for software applications?
Well, this is a huge topic, worthy of a book, and in fact Michael T. Nygard has already written it: the fantastic book Release it!. I really urge you to buy it right now if you haven’t read it yet.
The really short version is that being resilient in the context of microservices is to be able to bounce back if things in your deployment environment starts to misbehave. I.e. to be able to serve request in a timely manner during the incident (probably with limited functionality), and then function as normal after the situation has been resolved.
There are of course many ways to misbehave in the context of microservices (or more genarally in the context of distributed systems), but the worst is to be slow when handling requests. Or actually even worse, to accept the request and then fail slowly.
Why is this bad?
Well, slowness has a tendency to spread in a microservice architecture. In the next section we look at an example of a cascading failure.
Cascading failures
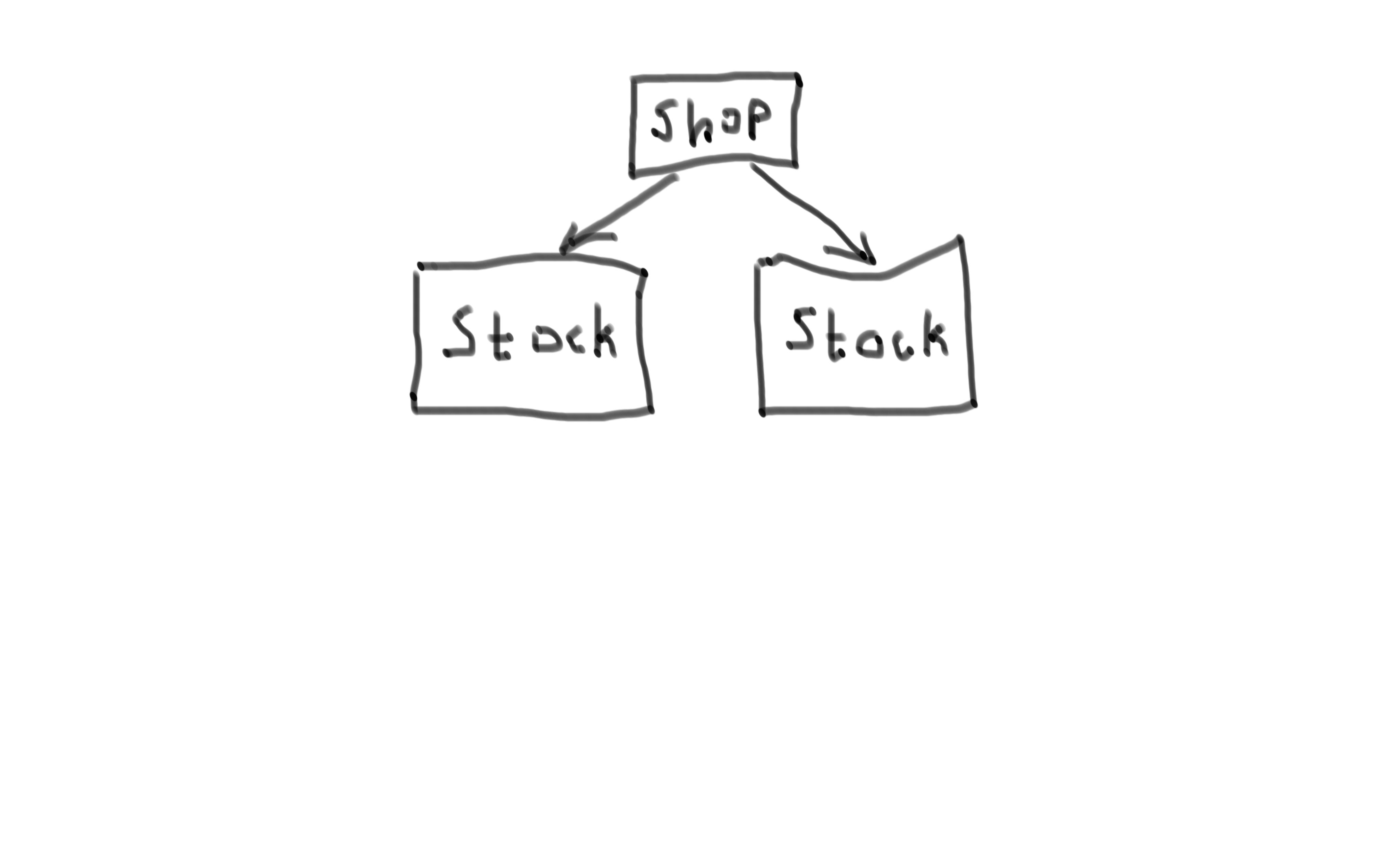
So lets say that you have your system A that is dependent on the system B.
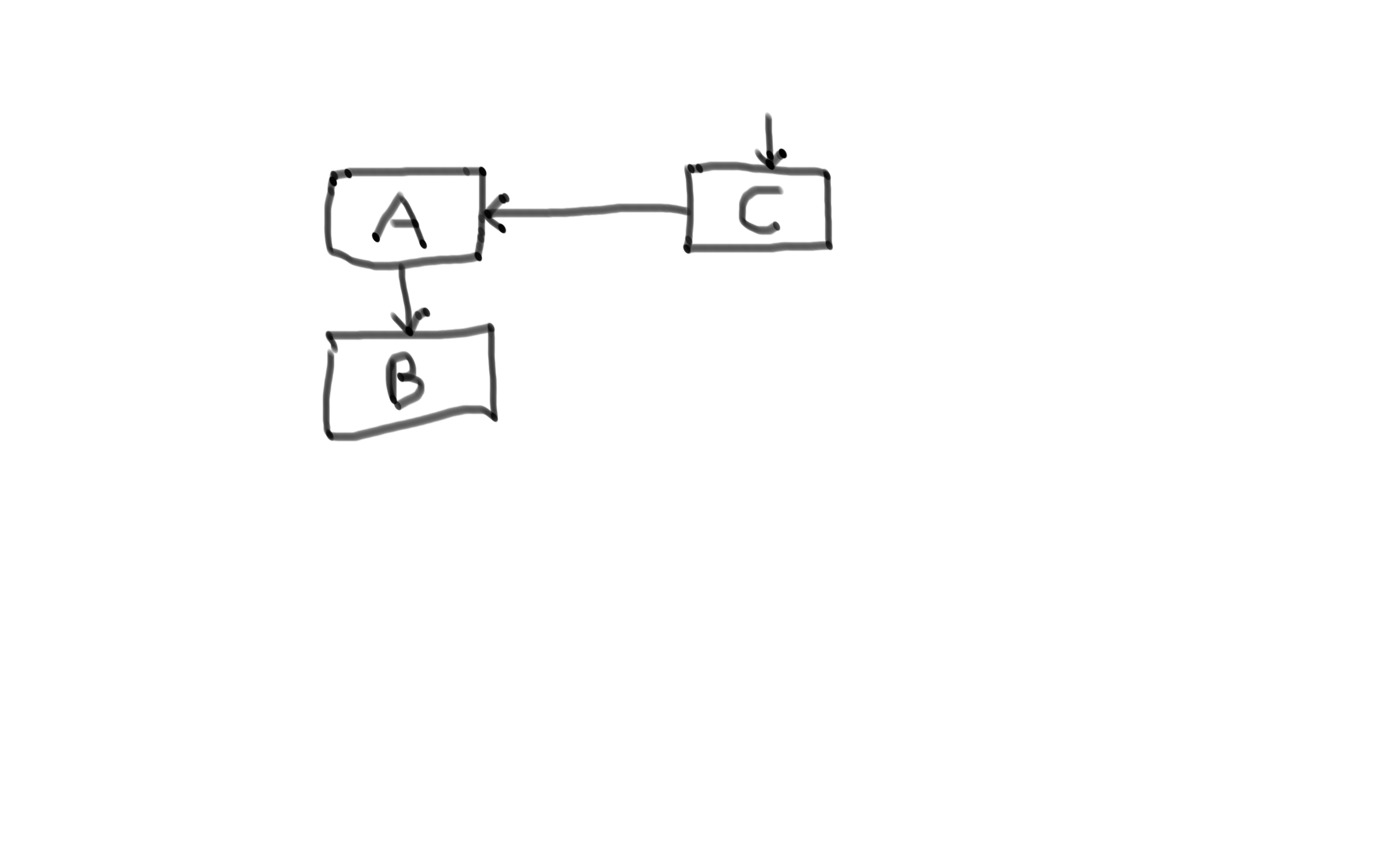
During high traffic situations service B becomes slow.
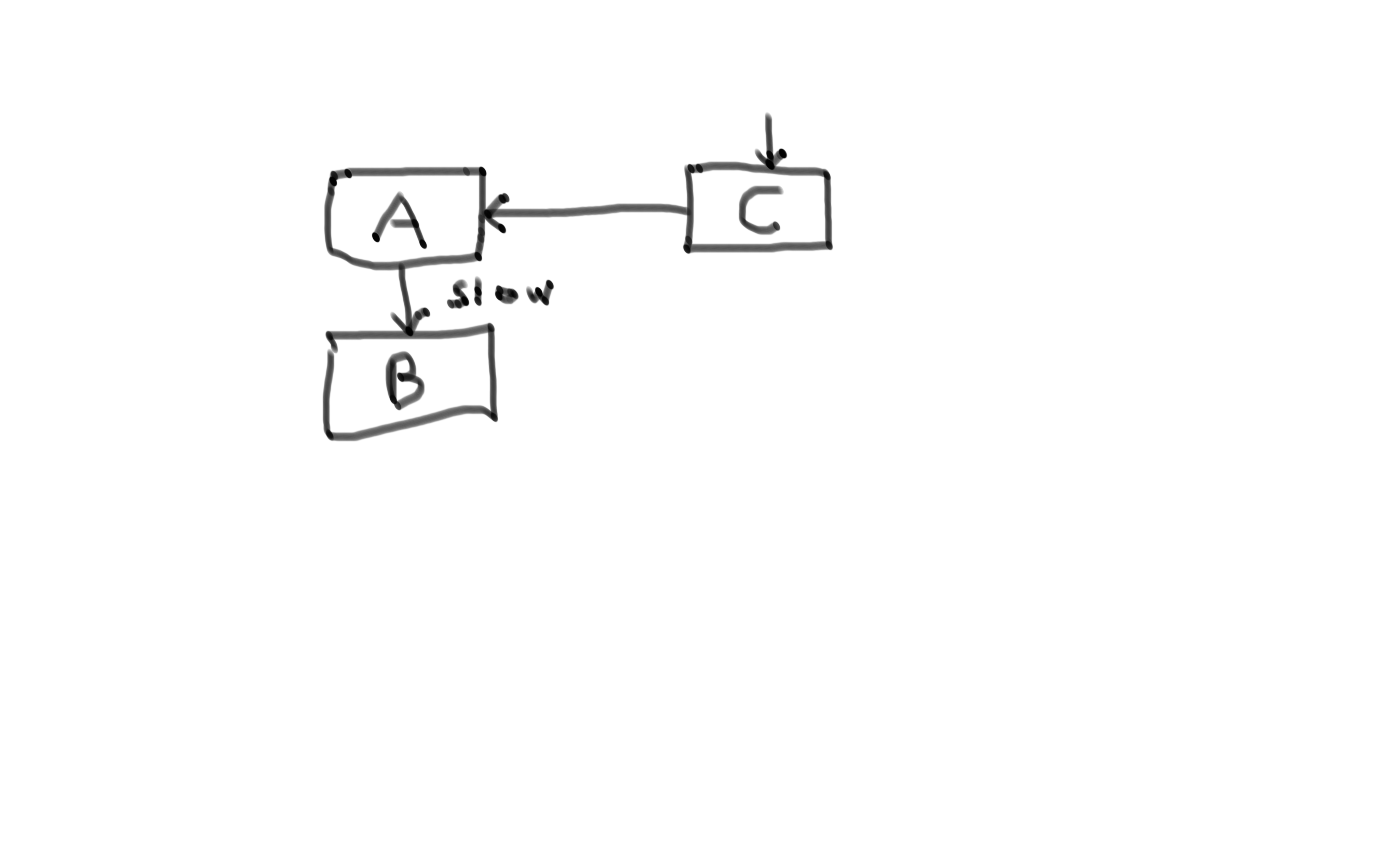
This in turn makes the service A slow and then in turn service C.
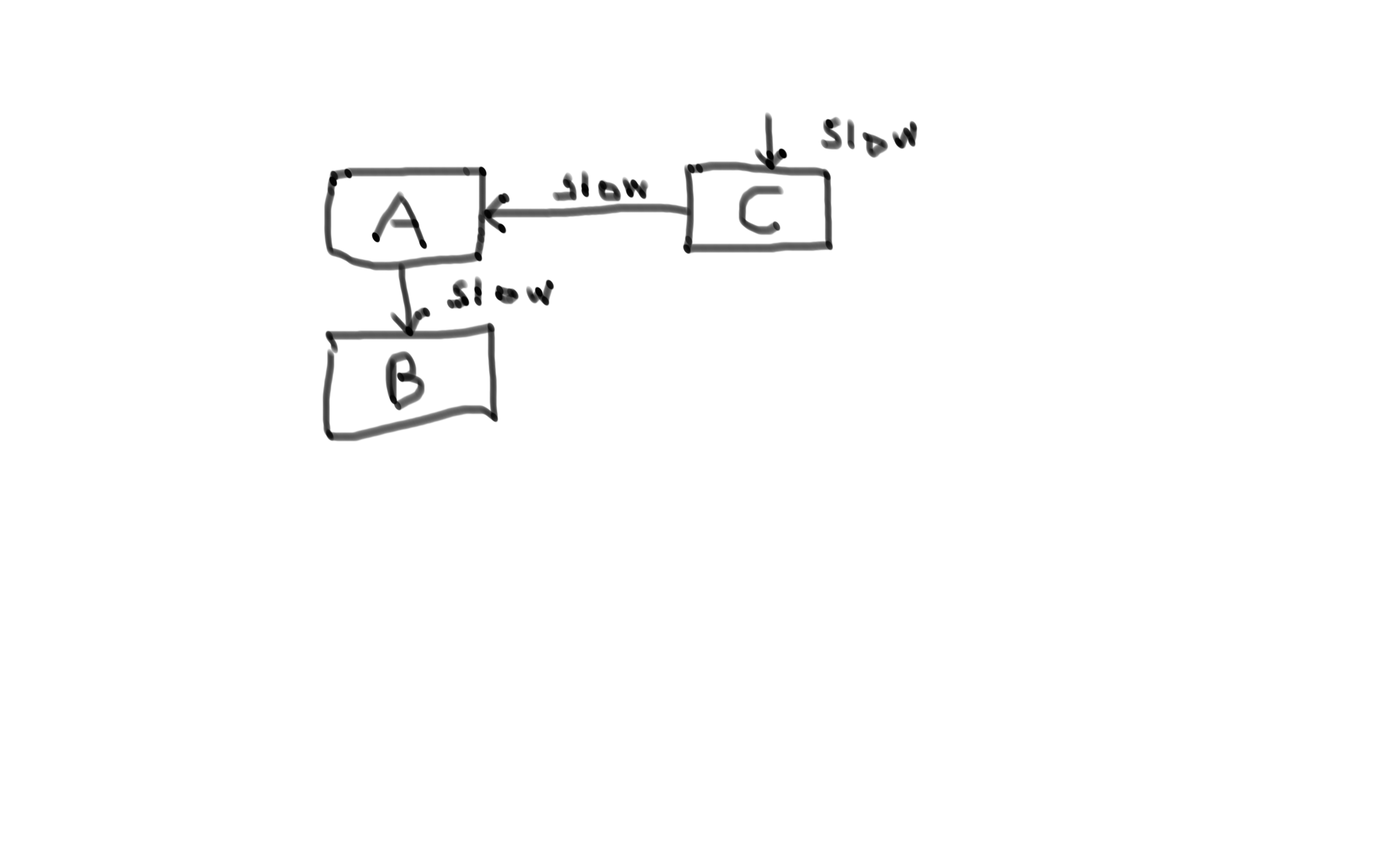
And there you have your cascading failure! But is it a problem? Well, replace system B with a database, system A with a stock service, C with a webshop and the high traffic situation with black friday and then you have a problem.
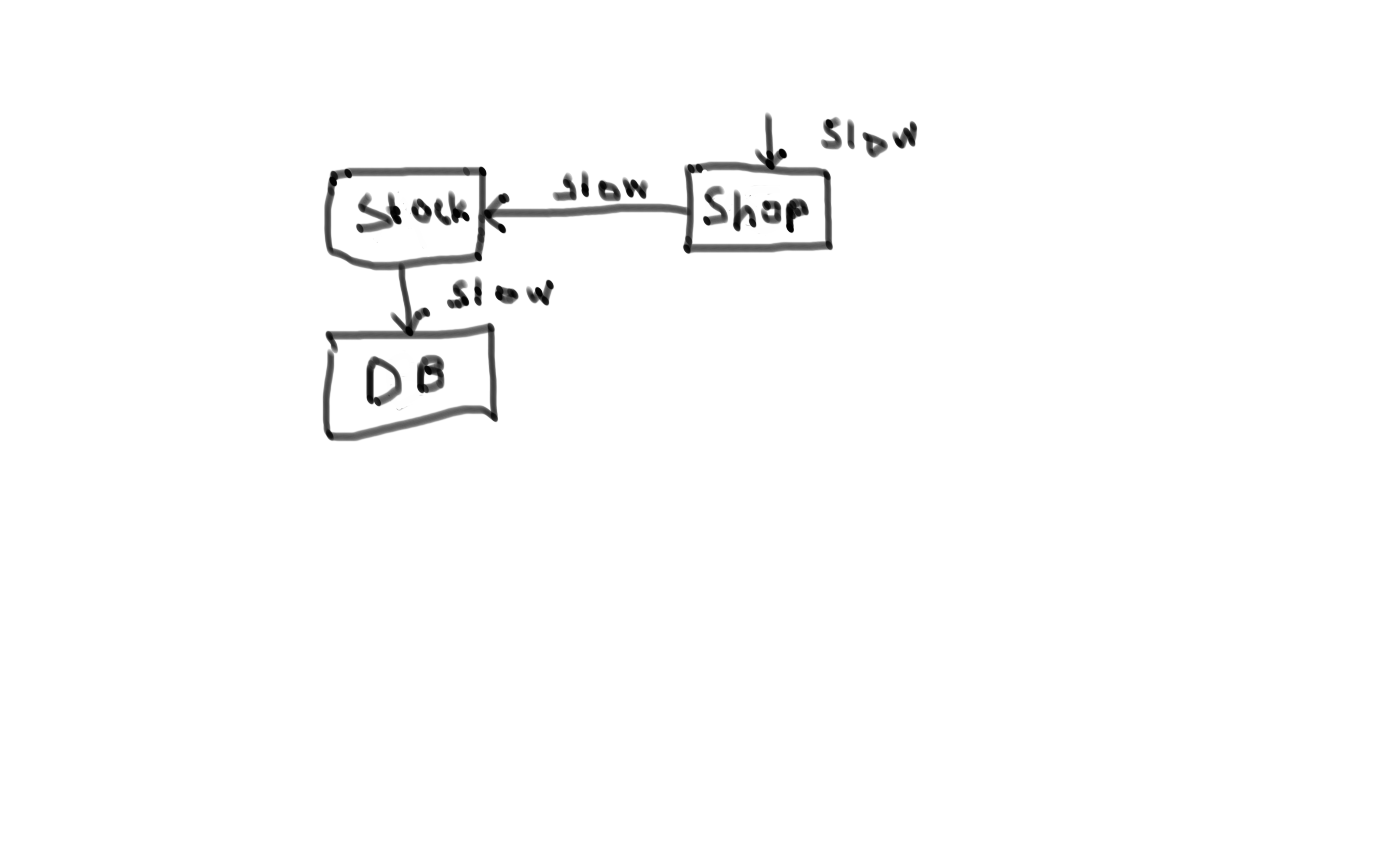
This is bad, in fact to be perfectly clear:

So here you have a distributed system that lacks resilience. Could we improve this? Yes! How?
Stop the cascading failure with a timeout
The reason the webshop calls the stock service is to be able to warn the customer if an item is out of stock. Depending on the context it might be better to show slightly outdated stock information for the customer then to not be able to use the webshop during black friday. This should of course be a decision for the product owner.
I will use this webshop example throughout the post to make things more concrete. Further, to keep this really simple, the stock service only provide a single API GET stock for a one item. If the service returns Http status 200 then the item is in stock.
By the way, in the code examples below I’m using a mock service that I developed as a hobby project, the service makes it possible to define mock end points and a delay. It’s available here: mock service.
Ok, so lets say that the PO tells us it’s ok to just tell the customer that the item is in stock if we run into trouble.
Well, then a simple timeout with a fallback could be just the thing to save black friday.
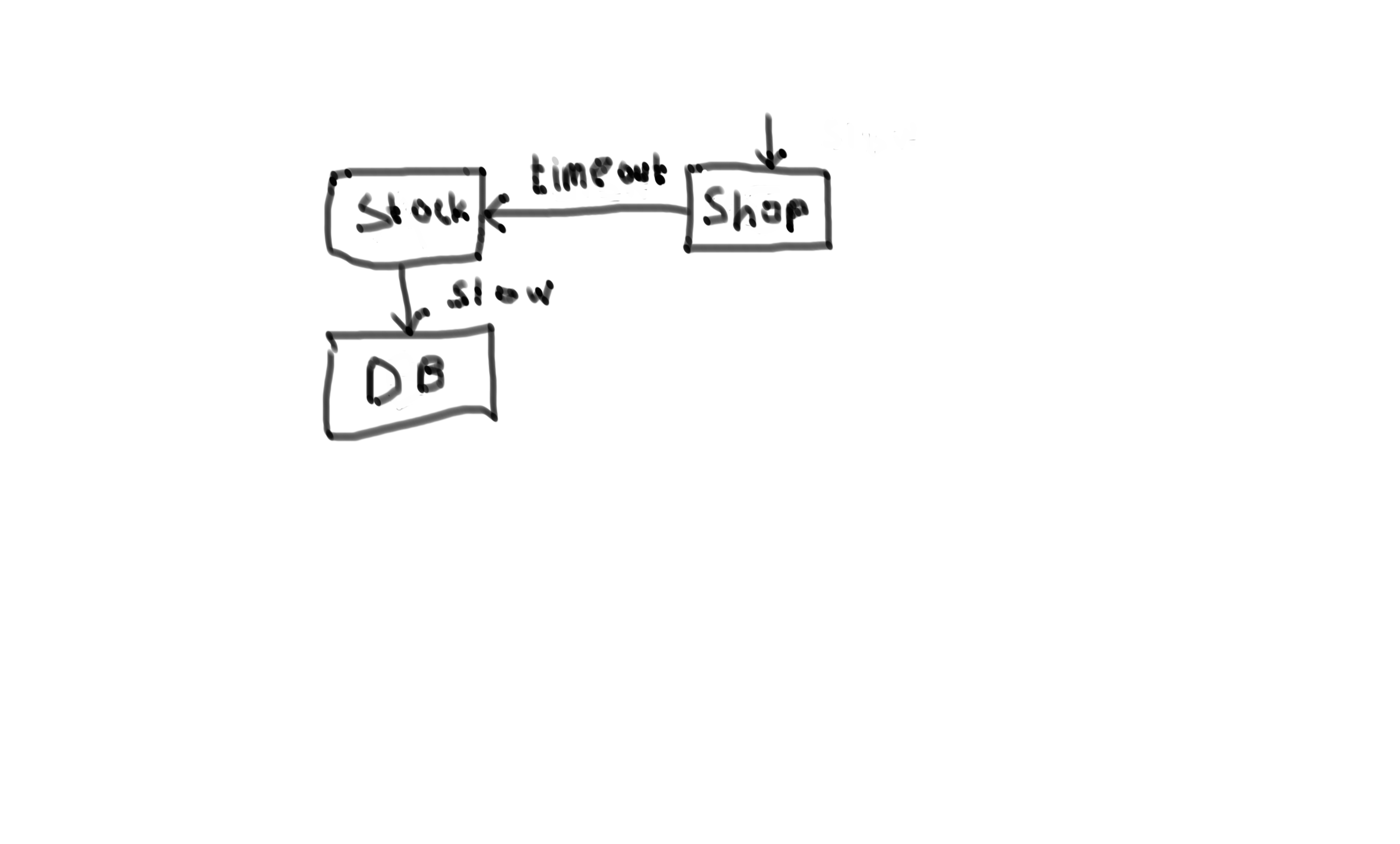
How does this look in the language of Finagle? First lets take a step back and do a call without a timeout and see what we can learn:
val client: Service[http.Request, http.Response] =
Http.client.newService("localhost:9000")
val request = http.Request(http.Method.Get, "/mock-service/stock")
val startTime = System.currentTimeMillis()
val response: Future[http.Response] = client(request)
println(s"After call to client: ${System.currentTimeMillis() - startTime} ms has elapsed")
val result = Await.result(response.onSuccess { rep: http.Response => println("GET success: " + rep) })
println(s"After await: ${System.currentTimeMillis() - startTime} ms has elapsed")
println(s"result: $result")The trace from running this program on my computer is as follows:
After call to client: 141 ms has elapsed
After await: 268 ms has elapsed
result: Response("HTTP/1.1 Status(200)")What have we learned?
First of all that a call to the client is non blocking, which we also can see by looking at what the client return when we call it: Future[http.Response].
Another learning is that it looks like Finagle does some sort of initialization (?) during the first call since the elapsed times are way higher than I expected.
Lets try and do two calls in a row:
first call
After call to client: 152 ms has elapsed
After await: 288 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
second call
After call to client: 2 ms has elapsed
After await: 3 ms has elapsed
result: Response("HTTP/1.1 Status(200)")Yes, the second attempt was faster!
What happens if we let the mock delay the response for a minute?
After call to client: 153 ms has elapsed
After await: 60310 ms has elapsed
result: Response("HTTP/1.1 Status(200)")Then we have to wait for a minute to get the response. In the webshop example above this is to slow! Lets add a timeout of 200 ms.
val client: Service[http.Request, http.Response] = Http.client
.withRequestTimeout(200.millis)
.newService("localhost:9000")
val request = http.Request(http.Method.Get, "/mock-service/stock")
val startTime = System.currentTimeMillis()
val response: Future[http.Response] = client(request)
println(s"After call to client: ${System.currentTimeMillis() - startTime} ms has elapsed")
val result = Await.result(response)
println(s"After await: ${System.currentTimeMillis() - startTime} ms has elapsed")
println(s"result: $result")And the trace:
After call to client: 144 ms has elapsed
Exception in thread "main" com.twitter.finagle.IndividualRequestTimeoutException: exceeded 200.milliseconds to localhost:9000 while waiting for a response for an individual request, excluding retries. Remote Info: Upstream Address: Not Available, Upstream id: Not Available, Downstream Address: localhost/127.0.0.1:9000, Downstream label: localhost:9000, Trace Id: 0f0aad9c2da112eb.0f0aad9c2da112eb<:0f0aad9c2da112ebOk, now we get a timeout, but the program was aborted since we got a IndividualRequestTimeoutException. This is maybe ok, but in this case we would like to do a fallback:
val response: Future[http.Response] = client(request).rescue {
case _: IndividualRequestTimeoutException =>
val fallbackResponse = Response()
Future(fallbackResponse)
case e: Exception => throw e
}After call to client: 146 ms has elapsed
After await: 452 ms has elapsed
result: Response("HTTP/1.1 Status(200)")Have we rescued black friday? Yes! Could we do better? You bet!
Stop calling the slow system with a circuit breaker
The change above is a good beginning but we can do better! Wouldn’t it be nice if we could decrease the traffic to the slow system? Then maybe it would heal itself?
If we just set a timeout we will still call the slow system even if it’s very likely that the request will timeout. This is bad in two ways, first of all we are still using resources of the slow system, on top of that we have to wait for the request to timeout. So lets introduce a circuit breaker!
But first of all what is a circuit breaker? It’s a construct that has three different states: Closed, Open and Half open.
In state Closed it let all calls from the client to pass through to the service. The circuit breaker is configured with a threashold, if that is broken we change state to Open.
In state Open it fails fast. Once in a while it chages state to Half open.
In state Half open we try to let a request through to the service. If it is a success (configured threashold) we change state to Closed, if it is a failure we change back to Open.
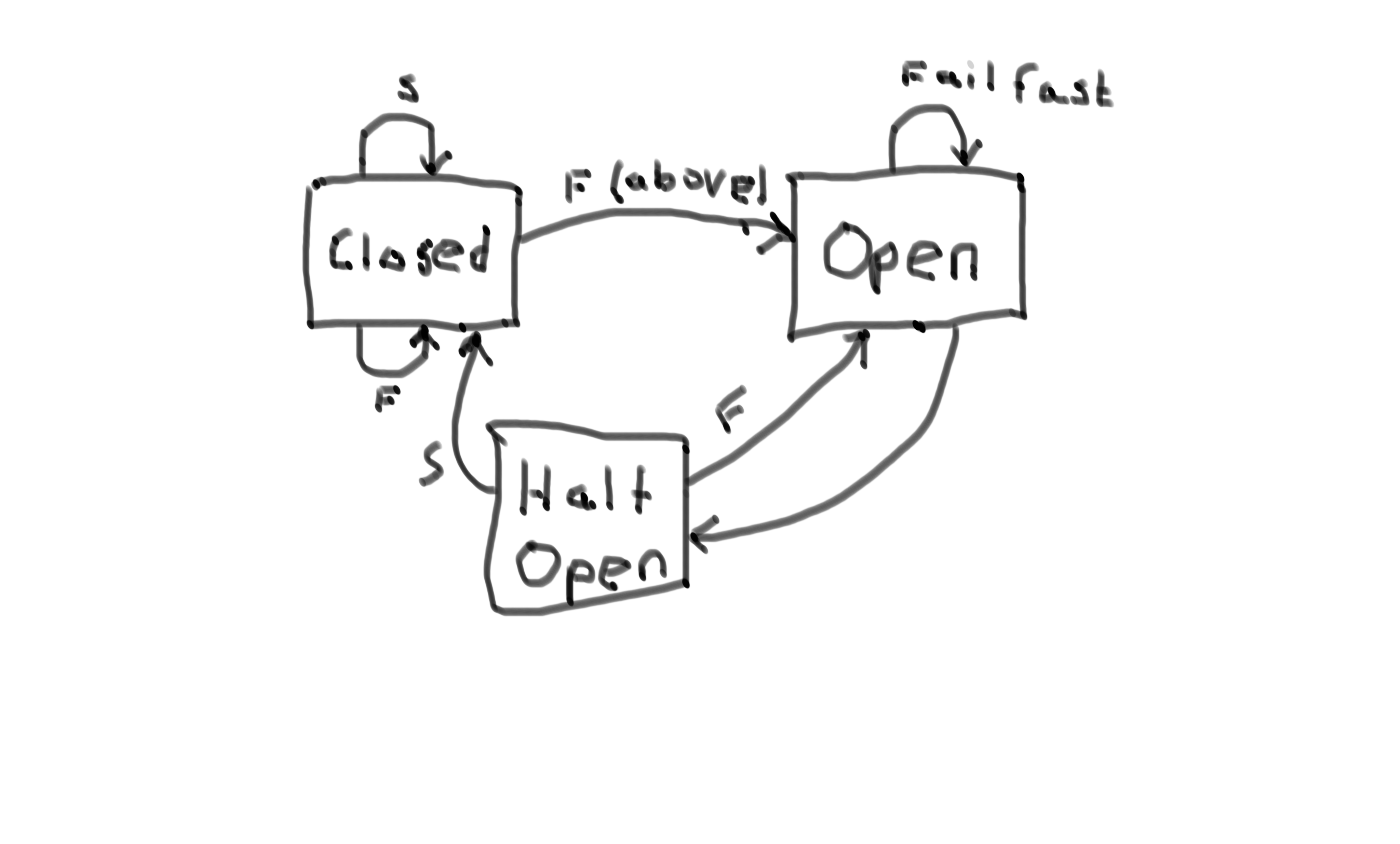
I noticed that the default behaviour for a Finagle circuit breaker is not to fail fast so I had to override that:
val client: Service[http.Request, http.Response] = Http.client
.configured(WhenNoNodesOpenParam(WhenNoNodesOpen.FailFast))
.withRequestTimeout(200.millis)
.newService("localhost:9000")
val request = http.Request(http.Method.Get, "/mock-service/test")
while(true) {
val startTime = System.currentTimeMillis()
val response = client(request).rescue {
case _: IndividualRequestTimeoutException =>
println(s"Got timeout after: ${System.currentTimeMillis() - startTime} ms")
val fallbackResponse = Response()
Future(fallbackResponse)
case _: NoNodesOpenException =>
println(s"No node available: ${System.currentTimeMillis() - startTime} ms")
val fallbackResponse = Response()
Future(fallbackResponse)
case e: Exception =>
println("hepp: " + e)
throw e
}
println(s"After call to client: ${System.currentTimeMillis() - startTime} ms has elapsed")
response.onSuccess(result => {
println(s"After await: ${System.currentTimeMillis() - startTime} ms has elapsed")
println(s"result: $result")
println()
})
Thread.sleep(1000)
}And here is a trace:
After call to client: 2 ms has elapsed
After await: 4 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
After call to client: 2 ms has elapsed
Got timeout after: 217 ms
After await: 219 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
After call to client: 2 ms has elapsed
Got timeout after: 217 ms
After await: 218 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
After call to client: 1 ms has elapsed
Got timeout after: 216 ms
After await: 216 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
After call to client: 1 ms has elapsed
Got timeout after: 217 ms
After await: 218 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
After call to client: 1 ms has elapsed
Dec 31, 2020 10:51:37 AM com.twitter.finagle.liveness.FailureAccrualFactory$$anon$3$$anon$4 didMarkDead
INFO: marking connection to "localhost:9000" as dead for 5 seconds. Policy: SuccessRateFailureAccrualPolicy(sr=0.8162510326043788, requiredSuccessRate=0.8), ConsecutiveFailureAccrualPolicy(consecutiveFailures=5, consecutiveFailuresThreshold=5). Remote Address: Inet(localhost/127.0.0.1:9000,Map())
Got timeout after: 209 ms
After await: 210 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
No node available: 1 ms
After call to client: 2 ms has elapsed
After await: 2 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
No node available: 1 ms
After call to client: 1 ms has elapsed
After await: 1 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
No node available: 1 ms
After call to client: 1 ms has elapsed
After await: 1 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
No node available: 1 ms
After call to client: 1 ms has elapsed
After await: 1 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
After call to client: 1 ms has elapsed
Dec 31, 2020 10:51:42 AM com.twitter.finagle.liveness.FailureAccrualFactory$$anon$3$$anon$4 didMarkDead
INFO: marking connection to "localhost:9000" as dead for 9 seconds. Policy: SuccessRateFailureAccrualPolicy(sr=0.6853904064376404, requiredSuccessRate=0.8), ConsecutiveFailureAccrualPolicy(consecutiveFailures=6, consecutiveFailuresThreshold=5). Remote Address: Inet(localhost/127.0.0.1:9000,Map())
Got timeout after: 215 ms
After await: 215 ms has elapsed
result: Response("HTTP/1.1 Status(200)")
No node available: 1 ms
After call to client: 1 ms has elapsed
After await: 1 ms has elapsedIn the trace we can see that we change state to Open and then start to fail fast. After a while we let a request through (i.e. change state to Half open). When the request fails we start to fail fast again.
Note that we fails really fast, in about 1 ms compared to 215 ms when we get a timeout which is good for the clients of the webshop.
Here is the view from the mock stock service:
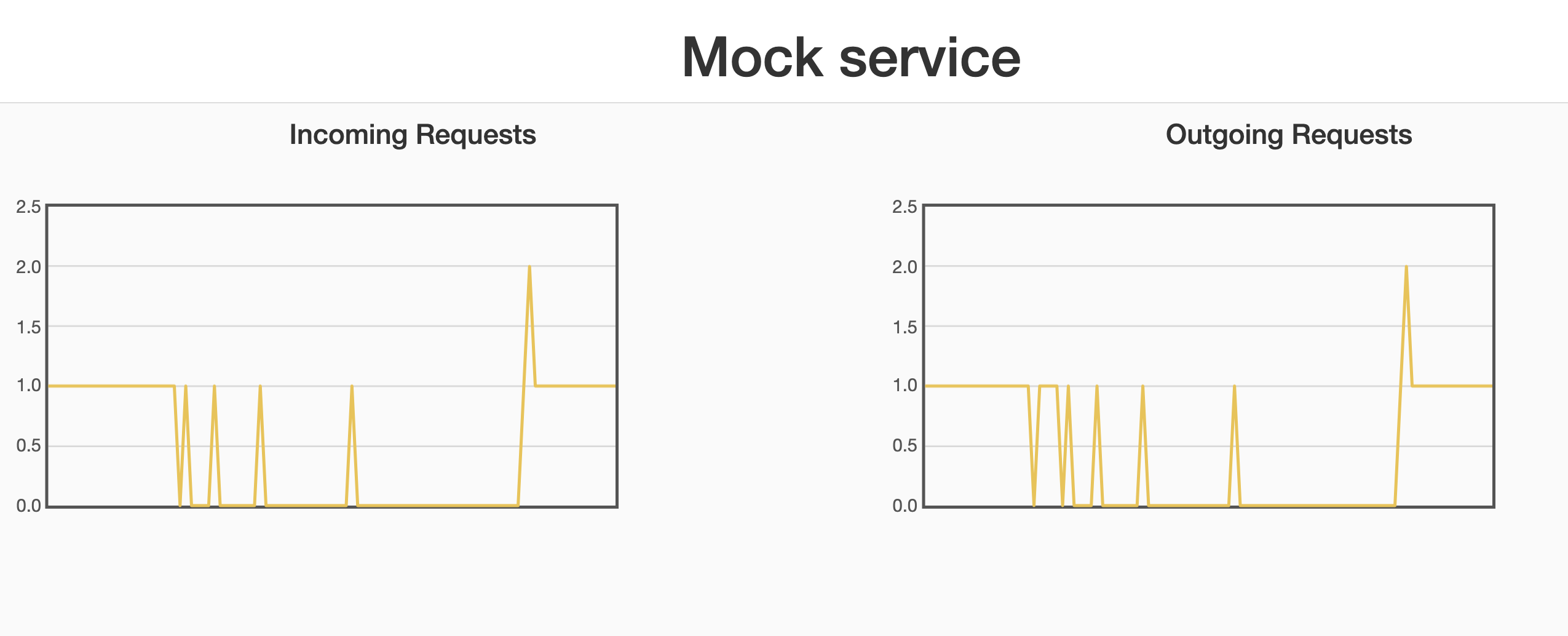
We can see that we receive a request from time to time in an increasing interval, we receive the requests when the Circuit breaker is in the Half open state. In the end when I changed the delay to zero again we started to receive requests once again.
This is nice, now we have saved black friday even more (not only a timeout, but also fail fast) and on top of that we have also been nice to our stock service. Are we still on the naughty list?

Seems that the jury is still out on this one. Can we do better? You bet!
Load balancing
Turns out that the Finagle client has support for load balancing:
Turn on the load balancing by adding another service when creating the client:
val client = Http.client
.configured(WhenNoNodesOpenParam(WhenNoNodesOpen.FailFast))
.withRequestTimeout(200.millis)
.newService("localhost:9000,localhost:19001")Lets repeat the experient above and let one of the services stat to misbehave:
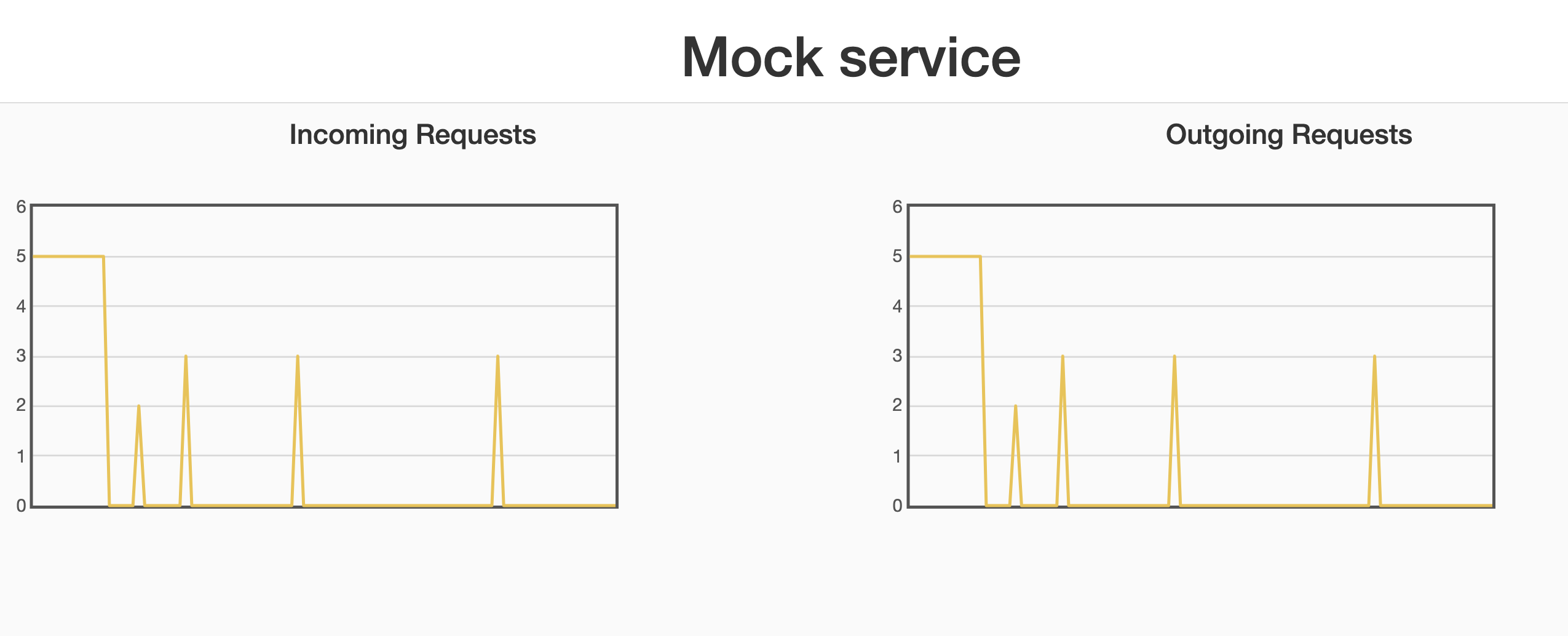
In the beginning of the experiment I set a delay of 0 ms in the mock on both the services. The load was evenly distributed (5 req/s) to each service.
After a while I increased the delay to 200 ms on one of the services. The Finagle client then started to route all the requests to the service that was still ok. We can also see that the circuit breaker pattern is still in use.
Later on I set the delay back to zero and the load was eventually once again distributed evenly between the services.
And now finally I think we are on the right list!

Conclusion
From what I can see Finagle supports the key functionalities for writing write resilient clients. There are many configuration options that I have not investigated yet but that will be for the future.
One might argue the it’s better to avoid RPC and use some sort of Messaging system instead (for example RabbitMQ) but if that’s not an option this looks like nice stuff.
The code is available at github
Happy coding!